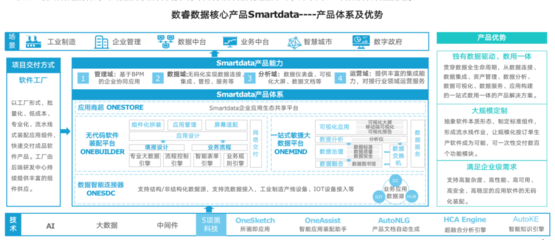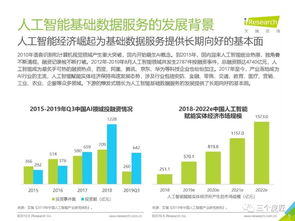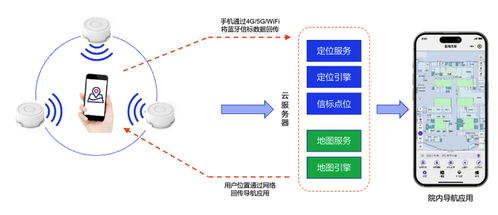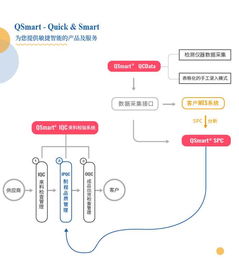
隨著金融行業數字化轉型的深入,業務系統日益復雜,運維監控面臨海量、異構、實時性要求高的數據挑戰。構建統一監控體系已成為金融機構保障系統穩定、提升運營效率的必然選擇,而運維數據治理則是這一體系的核心支柱。其中,數據處理服務作為治理落地的關鍵環節,直接關系到監控數據的質量、價值與可用性。
一、統一監控對運維數據治理的核心訴求
金融行業的統一監控旨在實現對基礎設施、應用性能、業務交易、安全態勢等的全景可視與智能分析。這要求運維數據必須具備:
- 統一性:來自網絡設備、服務器、數據庫、中間件、應用日志、業務指標等多源數據,需在格式、模型、語義上實現統一。
- 準確性:數據必須真實、完整、及時,任何失真或延遲都可能引發誤判,影響風控與決策。
- 關聯性:能夠跨系統、跨層級進行關聯分析,快速定位根因,例如將應用延遲與底層資源瓶頸相關聯。
- 合規性:需滿足金融監管機構對數據安全、隱私保護、審計留痕等方面的嚴格規定。
二、數據處理服務在運維數據治理中的核心功能
為滿足上述訴求,專業的數據處理服務需提供以下核心能力:
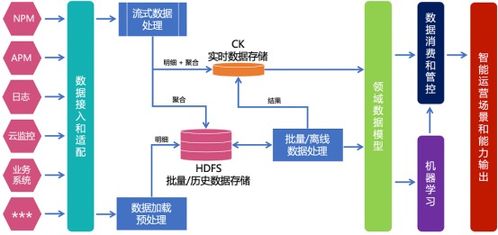
- 數據采集與接入:支持Agent、API、日志抓取、流量鏡像等多種方式,適配各類數據源,實現全量、實時、無損采集。
- 數據解析與標準化:對非結構化、半結構化日志進行智能解析(如正則解析、GROK模式),提取關鍵字段,并映射到統一的監控數據模型(如基于OpenTelemetry的標準)。
- 數據清洗與增強:過濾無效、重復數據,修復缺失值,并通過IP地理信息庫、CMDB配置庫等進行數據豐富,補充上下文信息。
- 數據關聯與聚合:基于時間戳、交易ID、主機IP等關鍵字段,實現跨源數據的關聯;按時間窗口、業務維度進行實時聚合,生成高階指標(如成功率、平均響應時間)。
- 實時流處理與計算:利用Flink、Spark Streaming等引擎,對數據流進行實時過濾、轉換、統計與告警閾值計算,滿足秒級監控需求。
- 數據路由與分發:將處理后的數據高效、可靠地分發給下游的監控分析平臺、告警引擎、數據倉庫或AIOps平臺,支撐不同場景的消費。
三、金融行業數據處理服務的實施路徑
- 制定數據規范與模型:首先定義企業級統一監控數據模型,明確數據分類、核心字段、質量標準與生命周期,這是所有處理流程的基準。
- 構建可擴展的管道架構:采用微服務化、容器化的數據處理流水線,實現采集、解析、清洗、計算等環節的解耦與彈性伸縮,以應對業務峰值。
- 嵌入數據質量監控:在數據處理各環節設置質量檢查點,監控數據流量、延遲、解析成功率、字段完整性等,實現數據質量的閉環管理。
- 強化安全與合規控制:對敏感信息(如用戶ID、交易金額)進行實時脫敏;確保數據處理過程符合內部合規與外部監管要求,并保留完整的審計日志。
- 與運維流程集成:將數據處理服務與事件管理、變更管理、容量規劃等ITSM流程打通,使高質量數據能直接驅動運維決策與行動。
四、未來展望:向智能與主動運維演進
隨著技術發展,數據處理服務將進一步融合機器學習能力,實現:
- 智能解析:自動學習日志模式,適應應用變更,減少人工維護成本。
- 異常檢測:在數據流中實時識別潛在異常模式,實現主動預警。
- 根因分析:自動關聯多維度數據,快速定位故障根源。
在金融行業統一監控的宏大架構中,運維數據治理是基石,而健壯、高效、智能的數據處理服務則是將原始數據轉化為運維洞察的“核心引擎”。金融機構需從戰略高度規劃其建設,通過標準化的模型、自動化的流程、持續的質量管理,確保監控數據可信、可用、有價值,最終賦能業務穩定與創新。